2.2. XML létrehozása
Feladatunk egy osztálynapló elkészítése XML adatbázisban, amit utána egy általunk írt Flash alkalmazás segítségével böngészni tudunk, lapozva a felvett diákok és átlagaik között.
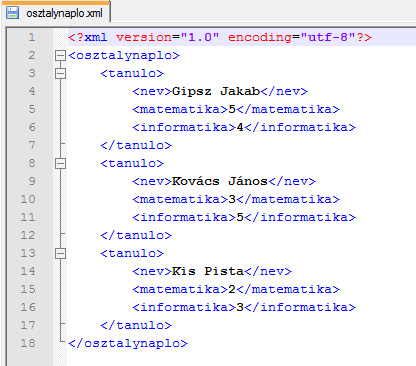
Hozzuk hát létre az adatbázist, amit használni fogunk. Bármely szövegszerkesztővel indítsunk egy új dokumentumot, és nevezzük el „osztalynaplo.xml"-nek!
6. ábra
XML adatbázis
Az első sort hívjuk az XML fejlécének:
<?xml version="1.0" encoding="utf-8" ?>
Ezzel közöljük a leendő feldolgozó programmal, hogy valóban XML dokumentumról van szó, a szabvány mely verzióját használjuk, és milyen karakterkódolással kezelje.
Ezek után szükségünk van egy „gyökér" elemre, ami magába foglalja a teljes adatrészt. Ezt hívjuk dokumentumelemnek:
<osztalynaplo></osztalynaplo>
Csakúgy, mint a HTML-ben, az elemek itt is „tag"-ekből épülnek fel. Minden adat rendelkezik nyitó, illetve záró tag-gel (illetve előfordulhat, hogy a két tag között nincs érték, ez esetben a nyitó részben egyből le is lehet zárni az elemet - erről később).
Ezek után jön az adatrész, amit hasonlóan adunk meg: egy „tanulo" elem megnyitásával közöljük az új tanuló felvételét, majd minden egyes adatát külön megcímezve, új elemekben tároljuk. Amennyiben nincs több adatunk az adott tanulóról, bezárjuk a hozzá tartozó tag-et.
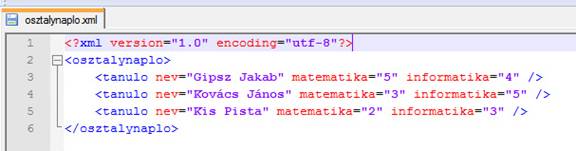
A HTML nyelvhez hasonlóan itt is lehetnek az elemeknek tulajdonságai („attribútumai"), amik további módszereket biztosítanak az adatok felvételére. A fenti adatbázist felépíthetnénk így is:
7. ábra
Alternatív XML felépítés
Ezzel a módszerrel nem az elemekbe írunk szöveget (illetve helyezünk el újabb elemeket), hanem attribútumokat adunk meg, és azokat látjuk el értékkel. Épp ezért nincs is szükségünk a nyitó és záró tag közötti helyre, így akár el is lehet hagyni a bezáró részt. A szabvány természetesen megköveteli, hogy minden nyitott elemet be kell zárni, de erre van lehetőség a nyitó tag-ben is: a bezáró reláció előtti / jel jelképezi az elem zárását.
A két módszert ízlés szerint lehet alkalmazni, akár vegyítve is. Az adatok mindenképp helyesen tárolódnak el, és mindkét esetben egyértelmű, jól felépített, és értelmezhető struktúrát lehet létrehozni. Igazán nagy különbség az adatok feldolgozásánál vehető észre, elvégre másképp eltárolt adatot másképp is kell kiolvasni.