2.3. Flash és XML
Most, hogy elkészült az adattárunk, hozzunk létre egy felületet Flash-ben, ami ezen adatokat meg tudja jeleníteni tanulónként. Szükségünk lesz három dinamikus szövegdobozra, amik kiírják az adatokat (nevezzük is el őket), illetve két gombra, amik segítségével a felhasználó oda-vissza tud lépni a tanulók között.

8. ábra
Flash felület terv
Ezek után ismét a kulcsképkocka szkriptablakában fogunk dolgozni. Első dolgunk az XML fájlunk betöltése. Hozzunk létre neki egy változót:
naplo = new XML();
naplo.ignoreWhite = true;
Ezzel létrehoztunk egy új objektumot, ami képes XML fájlokkal dolgozni. Az ignoreWhite tulajdonságát beállítottuk „igaz"-ra, ami annyit tesz, hogy a fájl felépítésében szereplő „whitespace"-k (szóköz, tabulátor, sortörés, amiket a formázás érdekében használtunk) nem lesznek figyelembe véve a beolvasás során. Töltsük be vele az előbb elkészített fájlunkat:
naplo.load(„osztalynaplo.xml");
A load metódus paramétereként adjuk meg a fájlunk elérését. Amennyiben egy mappában van a Flash fájlunkkal, elég csak a fájlnevet megadni.
Most, hogy létrejött a kapcsolat az XML fájl és a Flash alkalmazásunk között, írjunk egy eljárást, ami megjeleníti a felhasználó által látni kívánt rekordot. Hogy ez hányadik adat valójában, nyilván vezetnünk kell valahogy a programunkban. Erre vegyünk fel egy új változót:
hanyadik = 0;
Mivel a program indulásakor még biztos nincs felhasználói beavatkozás, megadunk neki egy kezdőértéket: 0-s index, vagyis az első elem az adatbázisban (mint az informatika nagy részében, itt is 0-ról kezdődik a számozás, tehát a 3 tanulós naplónk 0-tól 2-ig van sorszámozva). Ezek után készítsük el az eljárást, ami ezt a sorszámot figyelembe véve megjeleníti a hozzá tartozó adatokat az XML-ből:
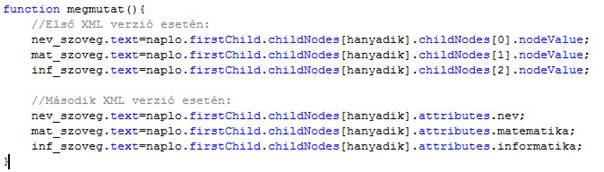
9. ábra
XML-ből kiolvasás két verzióban
Első ránézésre elég bonyolultnak tűnhet, de egyáltalán nem az. A reláció bal oldalán a szövegdobozaink nevei szerepelnek, amik megkapják az egyes adatokat. Jobb oldalon a napló XML fájlunk szerkezetét járjuk be, és a gyökerétől hivatkozunk a kívánt elemre. Haladjunk végig rajtuk:
- firstChild a tároló elem első „gyermek" elemére hivatkozik. Mivel ezt közvetlen az XML gyökeréből használjuk, az első gyermek a dokumentumelem lesz.
- childNodes[n] az adott elemen belüli n-edik elemre hivatkozik. Ezzel választjuk ki, hányadik tanuló adatait szeretnénk kinyerni, illetve, az első variációban, hogy adott tanuló hányadik adatát.
- nodeValue visszaadja adott elem értékét.
- attributes az adott elem attribútumaihoz fér hozzá.
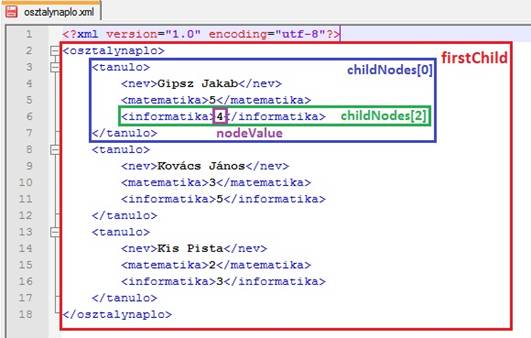
10. ábra
Első XML struktúra hivatkozásai
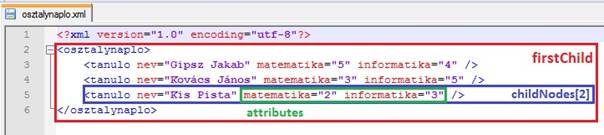
11. ábra
Második XML struktúra hivatkozásai
Ezzel az eljárással már képesek lennénk megjeleníteni az első elemet az XML-ből, azonban még egy gond akad: amennyiben közvetlenül a load utasítás után futtatjuk le az eljárást, igen valószínű, hogy hamarabb lefut, mielőtt teljesen betöltődik az adatbázis - és nem jelenik meg adat a képernyőn. Szerencsére le tudjuk ellenőrizni, mikor áll készen az adatbázis az onLoad esemény segítségével:
naplo.onLoad
= function(){
megmutat();
}
Így a megjelenítés közvetlenül a betöltés után hajtódik végre, amikor már biztos rendelkezésre állnak az adatok.
Ezek után már csupán annyi a teendőnk, hogy a gombok lenyomására növekedjen, illetve csökkenjen a számlálónk értéke, majd ismét lefuttatjuk a megjelenítő eljárásunkat az új sorszámmal. Arra persze oda kell figyelnünk, hogy ez a szám ne lépje túl a felvett elemek számát, és negatív se lehet. Épp ezért csak akkor növekedjen, vagy csökkenjen, ha még van abban az irányban rekord.
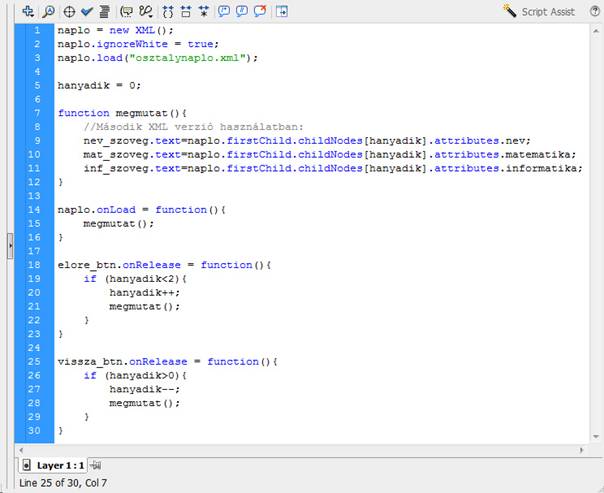
12. ábra
A szkriptünk végső kinézete